1. Introduction to L7|ESP¶
Enterprise Science Platform (L7|ESP) is a single solution to manage modern data-intensive laboratory operations. From entity submission/tracking to lab processing/analysis to reporting, L7|ESP is designed to reflect the way entities flow through a laboratory. L7|ESP can be used to manage laboratory Workflows and Analyses directly, and can also integrate with third party tools via APIs or Pipelines. Plus, every aspect of L7|ESP is customizable, providing you with the building blocks to structure L7|ESP around your lab's specific operations and environment, rather than having to adapt to a pre-structured software.
The diagram below illustrates how various elements of L7|ESP align with entity processing.
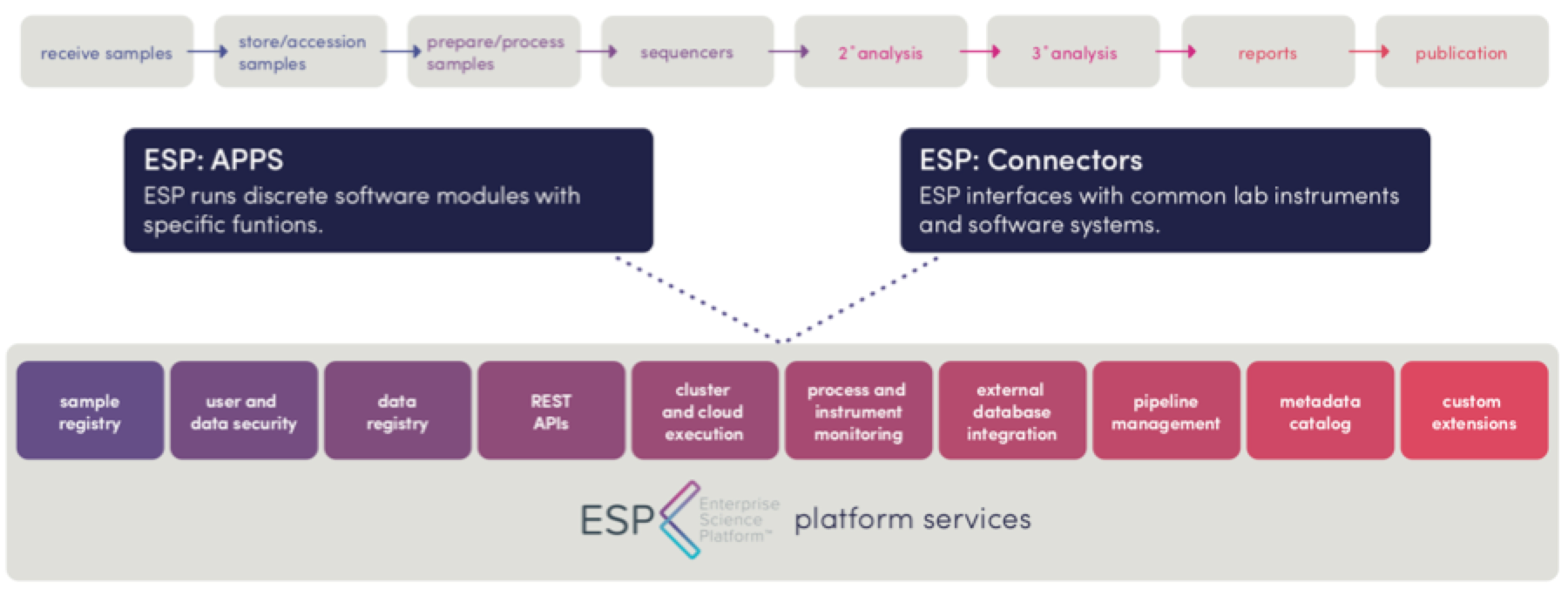
Every major element in L7|ESP addresses a specific aspect of lab processing to streamline various processes and results in a single, unified laboratory informatics solution.
A main element in L7|ESP is the Resource Manager, which is a general purpose database to create registries that track Entities, data, Containers, and any other Resources essential to lab operations. Once a Resource is registered in L7|ESP, the Resource Manager builds a detailed Provenance Graph and Audit Trail, allowing you to view the complete history and context of that Resource. Registries for Entities and Files are available in Resources.
Tracking resources is the first level of managing entities in a lab. Managing actual flow of lab operations is the second level. Workflow Engine is a general purpose Workflow management tool that tracks Entities as they move through laboratory Protocols. Unlike traditional LIMS or pipeline managers, L7|ESP treats both laboratory tasks and computational tasks as equals. Workflow Engine provides the main mechanism for capturing human-oriented, process-driven tasks (e.g., performing assays, running instruments, etc.) and integrates computational tasks defined using Pipeline Manager.
The home screen provides access to different functional elements.
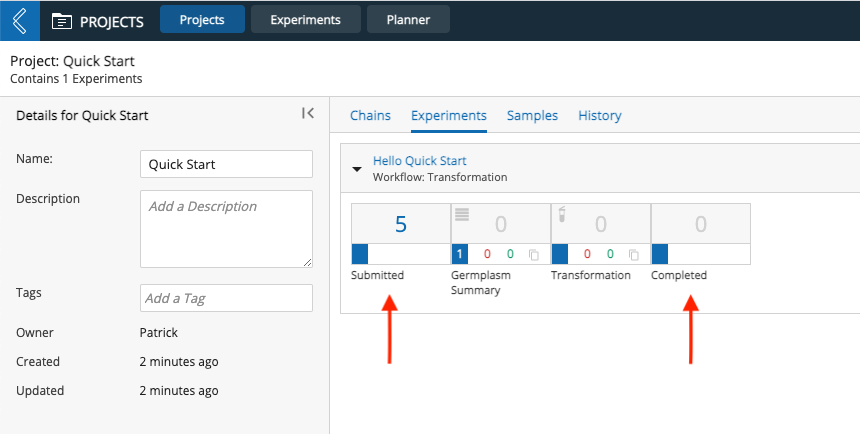
Each stage in a Workflow captures laboratory Protocol(s). The simple Workflow below shows that five Entities were submitted and are awaiting to be processed. The final Protocol is a computational (i.e., Pipeline) Protocol that generates a Report.
Pipeline Manager manages computational Pipelines. Pipeline Manager can integrate clusters, job schedulers, or public/private/hybrid clouds to ensure high levels of performance that match your computational needs.
The most important outputs of a lab are the results generated from the workflows. Reports Engine is browser-based reporting that allows you to build and manage interactive Reports, tied directly to Entity and Analysis results. Reports are highly customizable and can be used to create simple information displays or complex data portals that interact with third party applications and databases.
Combined, these elements are the foundation of L7|ESP, providing a robust platform for building complex scientific Workflows.
The sections to follow introduce key elements in L7|ESP and illustrate how they fit into different aspects of laboratory operations.
1.1. L7|ESP Terms¶
L7|ESP uses many common terms to refer to specific elements in the system. L7|ESP-specific terms are capitalized throughout this guide to distinguish them from their common definitions. For example, "A laboratory protocol can be captured in a Protocol and then grouped into a Workflow." In this example, "laboratory protocol" refers to a general lab procedure whereas "Protocol" refers to the Protocol app in L7|ESP.
Below is a list of L7|ESP-specific terms used in this guide.
Entity (Previously "Sample"): Physical entity registered in L7|ESP (e.g., raw sample, aliquot, patient, etc.).
Experiment: Each instance of a Workflow, as applied to a particular set of Entities. When a new Experiment is created, a set of Entities is associated with a specific Workflow. As the Experiment proceeds, the Entities move from Protocol to Protocol through the Workflow until the Experiment is finished.
File: Reference to a file registered as a Resource and its associated meta-data.
File Registry: Meta-data service that tracks Files on the relevant File system. Files can be registered manually via the command line or automatically when a Task is executed. Data provenance is made possible through the File Registry.
Pipeline: Ordered collection/sequence of one or more Tasks executed on compute resources. A Pipeline refers to processes controlled by a computer. Pipelines can have Tasks that execute one after another (serial), at the same time (parallel), or a combination of both. L7|ESP Pipeline Engine ensures that Tasks are executed in the proper order. Pipeline execution is integrated directly into LIMS.
Project: Grouping mechanism for Experiments, Pipelines, Entities, Reports, etc.
Protocol: Sequence of steps/actions performed on an Entity (e.g., library prep protocol or a quality control assay protocol). Protocols allow for direct embedding of lab procedural steps and documentation. Protocols define the data to collect while performing the protocol. Protocols can be used to launch Pipelines, directly integrating analysis into laboratory Workflows. There are 3 types of Protocols in L7|ESP, which can be combined in different ways to create Workflows to capture complex laboratory processes:
Standard Protocols are for entering data from ordinary lab procedures.
Pipeline Protocols launch Pipelines associated with an Entity or a group of Entities. Pipeline Protocols allow users to run Pipelines as part of a larger Entity-processing Workflow.
Sample Protocols set relationships between Entities and child Entities using Entity Types. For example, fan-in combines Entities to create a child Entity, while fan-out splits an Entity into separate child Entities.
Provenance Engine: Allows the user to build complete Provenance Graphs for Entities, which track all related Entities, Workflows, Protocols, Pipelines, and Files.
Report: Collection of visual elements that display results from a Pipeline.
Task: Smallest unit/computational step/building block in an L7|ESP Pipeline. Tasks are shell script that can run on available compute resources (e.g., clusters, clouds, or directly in L7|ESP).
Versioning: Essential aspect of maintaining proper provenance and for creating valid Audit Trails. L7|ESP keeps track of all previous versions of executed Pipelines and Tasks. In addition to aiding with compliance, L7|ESP's versioning engine allows a user to refer back to previous versions and determine how a particular result was generated. Versioning is used throughout L7|ESP to ensure that the user always has an accurate record of Analyses and Workflows.
Workflow: Ordered collection/sequence of Protocols. Workflows let the user define the order that the Protocols are executed while processing Entities. Workflow refers to a process controlled by a human.
Worksheet: Collection of Entities that are processed together by a lab technician. Worksheets can include Entities from multiple Experiments, as long as the Experiments are for the same version of the same Workflow. Worksheets use a spreadsheet-style view for data entry; this compact interface allows for rapid and easy data entry for multiple Entities, and streamlines the process to ensure that LIMS is not a bottleneck in the lab.
Below is a high-level diagram that shows the general relationship of important L7|ESP terms.
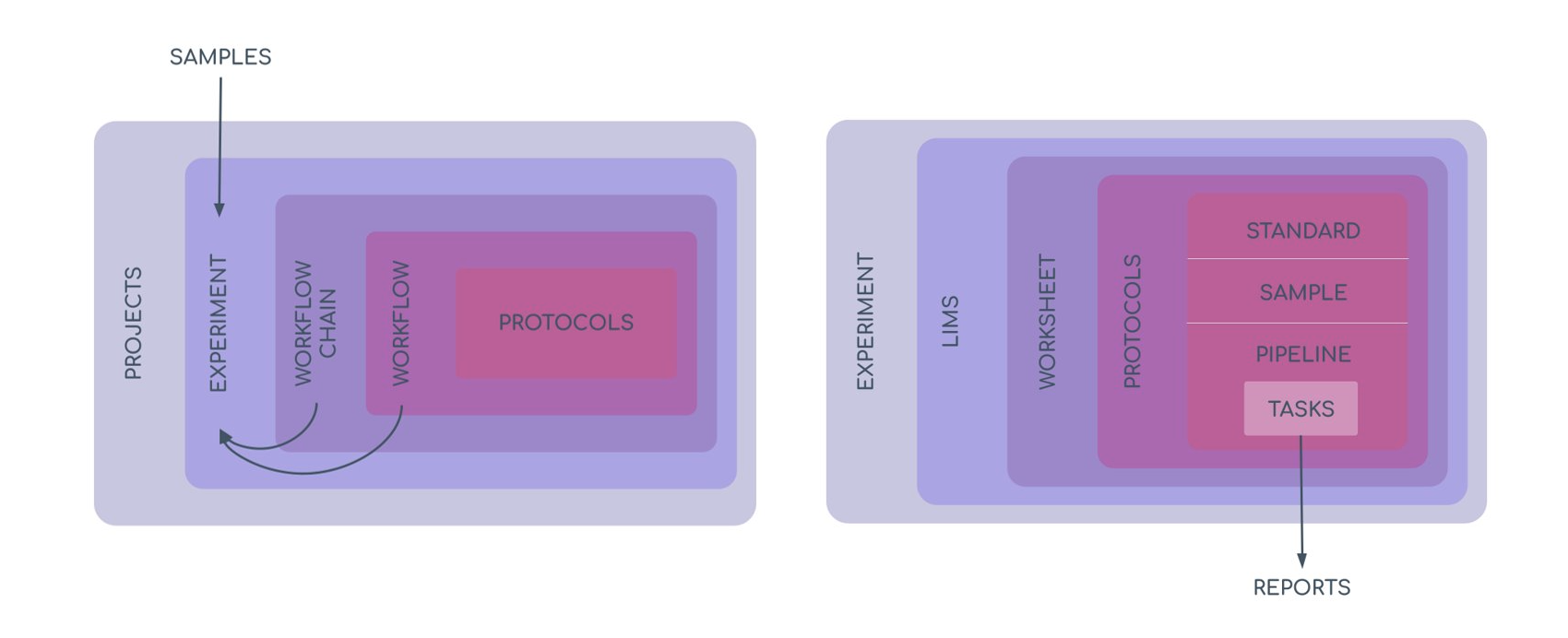
1.2. Provenance System¶
Maintaining a record of Entity and data provenance is essential for reproducible science. The better records are, the easier it is to replicate and explore previous results once work is completed. However, maintaining formal methods for tracking provenance can be challenging, especially in environments where record management includes multiple systems such as databases, notebooks, and "tribal knowledge."
L7|ESP provides a consistent record keeping system amongst lab personnel through its effective provenance system, which transparently tracks information as Tasks are performed, constantly records actions, and builds a detailed history of Experiments and processes. For all Workflows, L7|ESP maintains a robust Provenance Graph and Audit Trail.
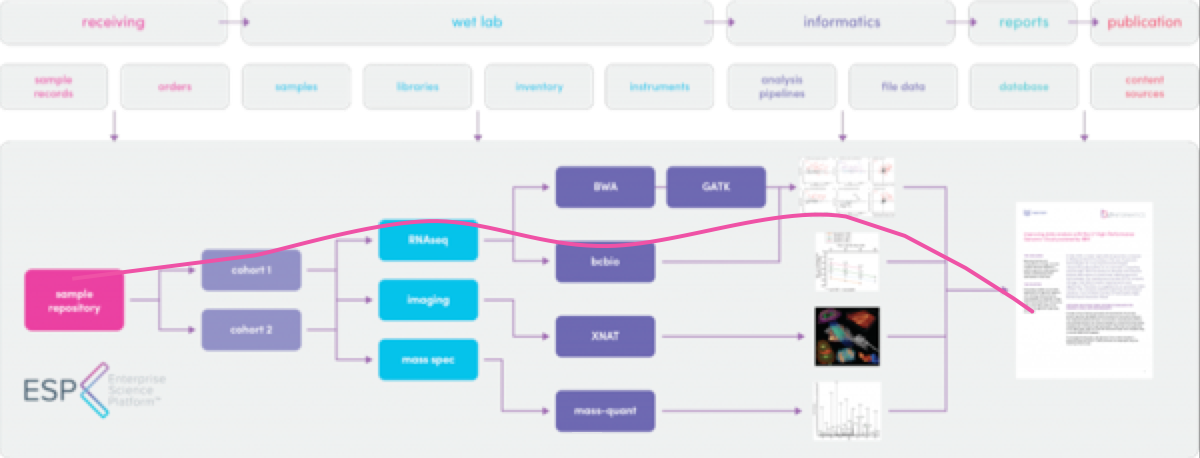
1.2.1. Data Provenance¶
The Provenance Engine works at multiple levels to track specific types of provenance data.
Audit Trails track changes and actions. A detailed history is tracked as users enter data and move Entities and data in L7|ESP.
The Provenance Graph tracks all dependency relationships between Entities, Workflows, Pipelines, Files, and any other Resources used in L7|ESP.
Both the Audit Trails and Provenance Graph are maintained transparently: you simply go about your daily tasks in L7|ESP and all provenance data is consistently recorded in parallel.
For example, after clicking an Entity, you are redirected to the Entity's page, which shows the Entity's dependencies that are tracked in the Provenance Graph and a detailed history of actions performed on the Entity.
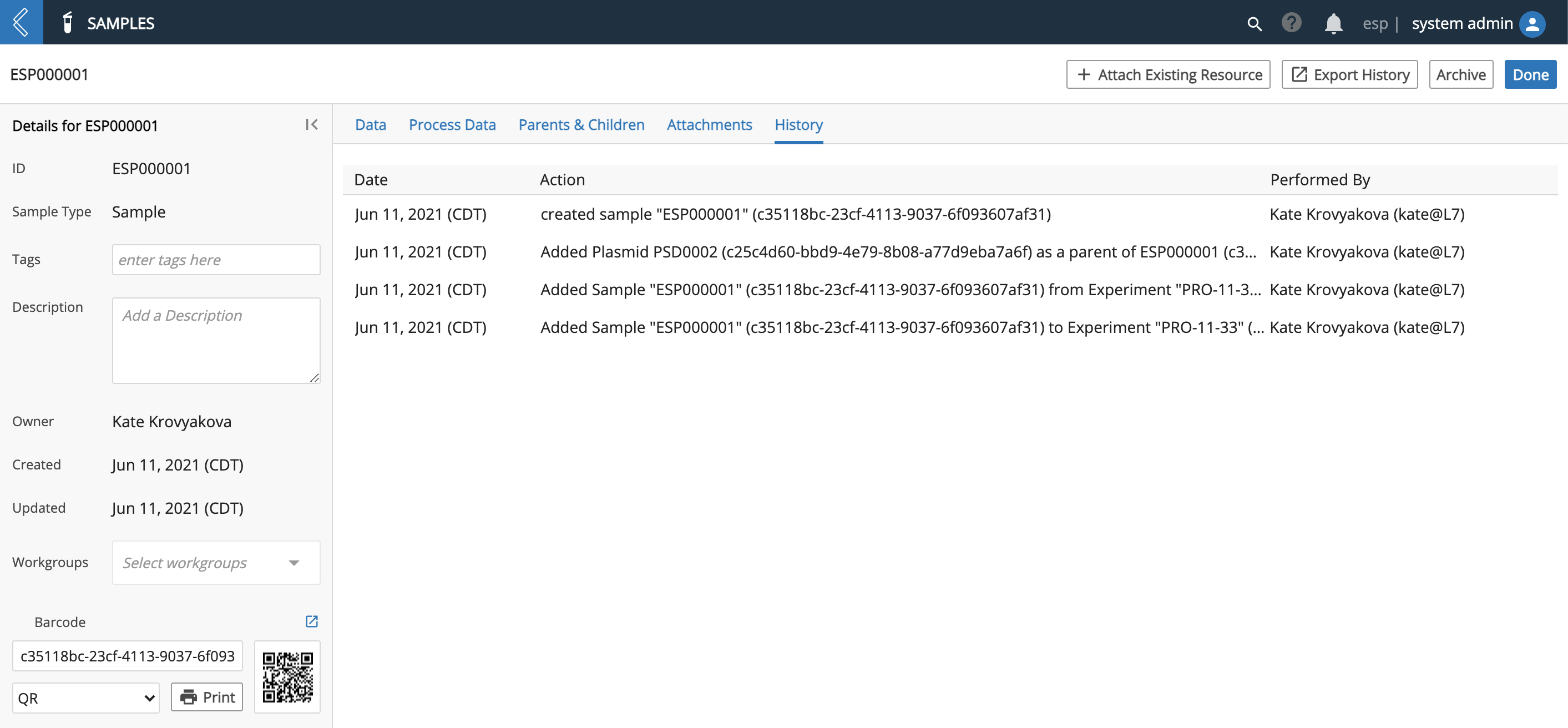
The Provenance Engine leverages Entities and File Registries to maintain dependencies between Entities and data generated by Analysis Pipelines. Physical entities and data files exist outside of L7|ESP; however, by registering Entities and Files in L7|ESP, the system can maintain the meta-data relationships between internal and external resources. Workflow Engine and Pipeline Engine include tools to automate registration of external resources.
1.2.2. Entity Lineage¶
Beyond basic operational provenance and auditing, Entities often have complex life cycles that are best tracked via lineages (rather than a general purpose Provenance Graph). To support Entity lineages, L7|ESP allows you to create parent/child relationships between Entities.
For example, consider the lineage of a particular sample taken from a cancer patient:
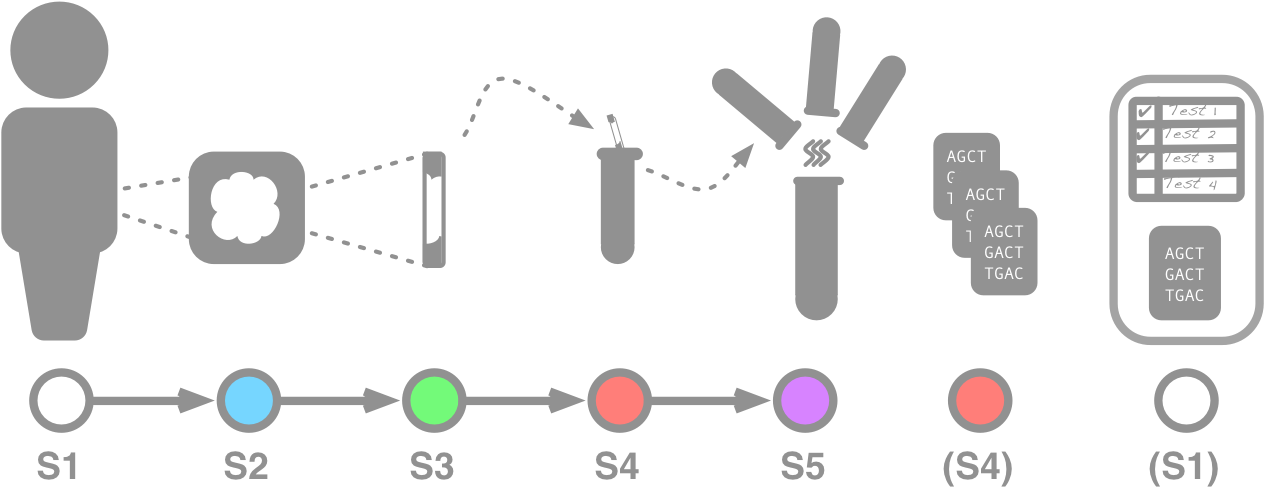
The patient (S1) has a tumor biopsy.
The tumor sample (S2) is prepared using FFPE.
A slice (S3) is removed from the FFPE block for sequencing.
A DNA library (S4) is prepared from the slice.
The DNA library is pooled (S5) with libraries from other samples for sequencing.
After sequencing, the data from the pooled sample (S5) is demultiplexed and associated back with the DNA Library (S4) for secondary analysis.
The results of secondary analysis on the DNA library (S4) are passed on to the tertiary analysis phase, where phenotypic data from the tumor sample (S2) is used to interpret the results.
The final report (with results and methods from all samples) is attached to the original patient's (S1) medical record.
In this example, five separate physical samples are created and used to diagnose the patient. Without a mechanism for tracking sample lineage, there is no easy way to trace a sample back to its source. Without a data provenance system tied to the sample lineage database, associating data with ancestral samples can be difficult.
L7|ESP vastly simplifies managing sample lineage with the following elements:
Entity Registry includes explicit notions of parent/child relationships among Entities.
Workflows can automatically register new child Entities as part of a Standard Workflow.
Workflows can automatically demultiplex pooled Entities, enabling automatic assignment of barcoded reads from pooled libraries back to the correct parent Entity.
L7|ESP can navigate an Entity's lineage to find data related to parent or child Entities. L7|ESP supports many parent/child relationships, allowing for many types of lineages as you need, including:

Single Parent/Child: A single child Entity is created from a parent Entity.
Single Parent, Multiple Children: Multiple aliquots are taken from a parent Entity.
Multiple Parents, Single Child: Parent Entities are pooled into a single mix.
Multiple Parents, Single Child Pool, Multiple Grandchildren: Grandchildren are related back to their proper pre-pooled parent.
Entity lineages can be created via the Entity page. On each Entity page there is a section for both parent and child Entities, along with an option to add new Entities to the relationships.
In many cases, Entity relationships are defined by the steps in a Protocol. In the above example, the biopsy, slicing, library prep, and pooling actions all create new samples. Rather than requiring the lab technician to manually update Entity pages to define these relationships, Workflow Engine utilizes a special type of Protocol: the Sample Protocol.
Sample Protocols automate the creation of child Entities in Workflows. When a Workflow includes a Sample Protocol, new Entities are created based on the parameters set in the Sample Protocol. As the Workflow progresses, you can assign the newly created Entities or the original Entities to subsequent Protocols within the Workflow. Note: A Sample Set is the term used in Workflows to identify the group of Entities to use in a Protocol.
Sample Protocols can be used to create single parent/single or multiple parent/single child relationships (pools), as well as unravel multiple parent/single child pool/multiple grandparent relationships (e.g., demultiplexing barcoded sequencing runs).
1.3. Versioning System¶
Laboratory and computational Resources in L7|ESP, such as Pipelines, Workflows, and Protocols, evolve over time. A Pipeline may have a new Task added or have some hard-coded parameters changed, or a Protocol may be updated to reflect new lab procedures. To ensure proper provenance when related Resources change, it is essential that all Resources involved in the object's Provenance Graph reflect the state of when they were added to the Provenance Graph (rather than the current state). To address this detail, L7|ESP has a robust versioning system for Resources.
Resource versioning is handled transparently from the user's perspective. L7|ESP keeps track of changes made to Workflows, Protocols, Pipelines, and Tasks. When a versioned Resource is used (e.g., an Entity is processed in a Workflow or a Pipeline is run), a reference is made in the calling object's Provenance Graph to the specific version of the Resource being used. If unused, intermediate versions are pruned from the database.
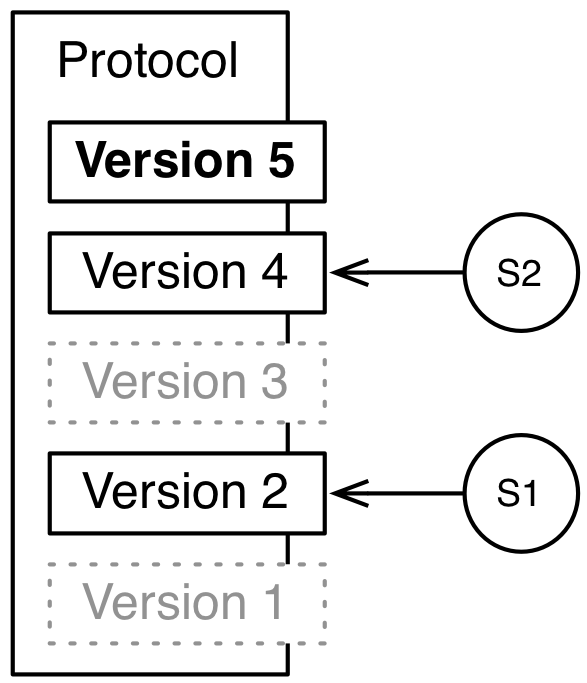
The Protocol in the figure illustrates L7|ESP's versioning. Version 1 was created by the user and then updated prior to the Protocol's first use. Additionally, Version 1 was used to process Entity S1 and added to S1's Provenance Graph. In L7|ESP, that version of the Protocol is available when reviewing provenance for S1. After some additional updates, the Protocol was used again to process Entity S2. Version 3, which was never used, was discarded, while Version 4 remains in L7|ESP. Version 5 is the current version of the Protocol and is used for Entity processing (or as the basis for further updates).
The versioning system in L7|ESP contributes to Provenance Engine and ensures that you will always have clear methods for traceability and reproducibility.